Journals > > Topics > Image Processing
Image Processing|99 Article(s)

Cancer Pathological Segmentation Network Based on Depth Feature Fusion
Hong HUANG, Tao WANG, Yuan LI, Fanlin ZHOU, and Yu LI
At present, image segmentation technology is more and more widely used in the auxiliary diagnosis and treatment of cancer. However, mature and advanced image segmentation methods are mainly focused on natural images. Compared with the natural image, the content of pathological image is more complex, and there are great differences between different images. At the same time, the cancer cells and normal cells in the pathological image are mixed with each other, and there are great similarities between the two cells. These characteristics make many excellent natural image segmentation algorithms can not be directly applied to the segmentation task of pathological images and achieve good performance, so that artificial intelligence algorithms can not be quickly applied to medical auxiliary diagnosis and treatment. Therefore, more accurate segmentation of tumor pathological images is of great significance to promote clinical cancer diagnosis.Aiming at the problems of multiple slice staining, large resolution difference and complex image content in medical pathological images, an improved hierarchical feature fusion segmentation method is proposed. The method mainly includes four parts: encoder, decoder, channel attention module and loss function. Firstly, the method selects U-Net network as the basic network structure. Efficientnet-b4 network is used to replace the original encoder of U-Net network for feature extraction, and the features are output from different layers as the output of the original encoder. The efficientnet-b4 network is transferred from natural images to pathological images for transfer learning, which effectively improves the ability of the network to extract effective features. In the decoder part, the feature fusion method is improved, and adds the hierarchical features of all layers before for feature fusion. Therefore, even the shallowest layer still contains the deepest global features. This method is used to gradually increase the role of global features in segmentation prediction from the deepest to the shallowest layer. It weakens the role of detail features in U-Net network. Therefore, the localization ability of the network on the main area of the lesion and the adaptability of the network to different resolution images are enhanced. At the same time, an improved channel attention module is used in each decoding layer, which is more suitable for pathological images than before. By adding global maximum pooling to extract channel features, more feature information is retained, so as to enhance the learning ability of the attention module and more effectively use the attention mechanism to filter the fused features. It highlights the effective features and suppresses the redundant features at the same time. In order to make the deep semantic information more distinguishable, the fusion characteristics of each depth layer are used to predict the output to construct a multi loss function. During training, the model performs prediction output at each decoding layer, and calculates the corresponding loss function for back-propagation training. Through this method, more effective deep semantic features are obtained for lesion location, which enhances the ability of the model to distinguish between normal and cancerous tissues, and improves the ability of the model to obtain and use global semantic features.Experiments are carried out on the BOT dataset and the seed dataset respectively. The Dice coefficient score of this method is 77.99% and 82.94% respectively, and the accuracy score is 88.52% and 87.42% respectively. Compared with U-Net and deeplabv3+, this method can effectively improve the segmentation accuracy and accuracy of tumor focus tissue, realize more accurate tumor location and segmentation in tumor pathological images, provide auxiliary support for doctors' clinical diagnosis more effectively, and improve the efficiency and accuracy of diagnosis and treatment. At the same time, ablation experiments are carried out on two data sets for the main improvements. The experimental results show the effectiveness of the improved method and can jointly promote the segmentation efficiency of HU-Net in pathological images from different aspects. At present, image segmentation technology is more and more widely used in the auxiliary diagnosis and treatment of cancer. However, mature and advanced image segmentation methods are mainly focused on natural images. Compared with the natural image, the content of pathological image is more complex, and there are great differences between different images. At the same time, the cancer cells and normal cells in the pathological image are mixed with each other, and there are great similarities between the two cells. These characteristics make many excellent natural image segmentation algorithms can not be directly applied to the segmentation task of pathological images and achieve good performance, so that artificial intelligence algorithms can not be quickly applied to medical auxiliary diagnosis and treatment. Therefore, more accurate segmentation of tumor pathological images is of great significance to promote clinical cancer diagnosis.Aiming at the problems of multiple slice staining, large resolution difference and complex image content in medical pathological images, an improved hierarchical feature fusion segmentation method is proposed. The method mainly includes four parts: encoder, decoder, channel attention module and loss function. Firstly, the method selects U-Net network as the basic network structure. Efficientnet-b4 network is used to replace the original encoder of U-Net network for feature extraction, and the features are output from different layers as the output of the original encoder. The efficientnet-b4 network is transferred from natural images to pathological images for transfer learning, which effectively improves the ability of the network to extract effective features. In the decoder part, the feature fusion method is improved, and adds the hierarchical features of all layers before for feature fusion. Therefore, even the shallowest layer still contains the deepest global features. This method is used to gradually increase the role of global features in segmentation prediction from the deepest to the shallowest layer. It weakens the role of detail features in U-Net network. Therefore, the localization ability of the network on the main area of the lesion and the adaptability of the network to different resolution images are enhanced. At the same time, an improved channel attention module is used in each decoding layer, which is more suitable for pathological images than before. By adding global maximum pooling to extract channel features, more feature information is retained, so as to enhance the learning ability of the attention module and more effectively use the attention mechanism to filter the fused features. It highlights the effective features and suppresses the redundant features at the same time. In order to make the deep semantic information more distinguishable, the fusion characteristics of each depth layer are used to predict the output to construct a multi loss function. During training, the model performs prediction output at each decoding layer, and calculates the corresponding loss function for back-propagation training. Through this method, more effective deep semantic features are obtained for lesion location, which enhances the ability of the model to distinguish between normal and cancerous tissues, and improves the ability of the model to obtain and use global semantic features.Experiments are carried out on the BOT dataset and the seed dataset respectively. The Dice coefficient score of this method is 77.99% and 82.94% respectively, and the accuracy score is 88.52% and 87.42% respectively. Compared with U-Net and deeplabv3+, this method can effectively improve the segmentation accuracy and accuracy of tumor focus tissue, realize more accurate tumor location and segmentation in tumor pathological images, provide auxiliary support for doctors' clinical diagnosis more effectively, and improve the efficiency and accuracy of diagnosis and treatment. At the same time, ablation experiments are carried out on two data sets for the main improvements. The experimental results show the effectiveness of the improved method and can jointly promote the segmentation efficiency of HU-Net in pathological images from different aspects.
Acta Photonica Sinica
- Publication Date: Mar. 25, 2022
- Vol. 51, Issue 3, 0310001 (2022)


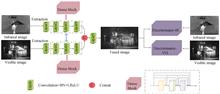
Infrared and Visible Image Fusion Method Based on Dual-path Cascade Adversarial Mechanism
Lili TANG, Gang LIU, and Gang XIAO
The thermal target information of infrared image and some detail information of visible images are usually ignored in image fusion method based on generative adversarial network. To address the problem, an infrared and visible image fusion method based on dual-path cascade adversarial mechanism is proposed. In the stage of the generator model, a dual-path cascade is used to extract features of infrared and visible images, respectively. To improve the quality of fusion, structural similarity is introduced into the loss function. In the stage of the discriminator model, a dual discriminator is used to distinguish the generated image from the true natural visual images. The proposed method is experimented on the public data, and compared with eight state-of-the-art image fusion methods. The experimental results show that the fusion image not only retains more the target information of infrared images, but also retains more detail information of visible images, which is superior to state-of-the-art methods in subjective evaluation and objective assessment. The thermal target information of infrared image and some detail information of visible images are usually ignored in image fusion method based on generative adversarial network. To address the problem, an infrared and visible image fusion method based on dual-path cascade adversarial mechanism is proposed. In the stage of the generator model, a dual-path cascade is used to extract features of infrared and visible images, respectively. To improve the quality of fusion, structural similarity is introduced into the loss function. In the stage of the discriminator model, a dual discriminator is used to distinguish the generated image from the true natural visual images. The proposed method is experimented on the public data, and compared with eight state-of-the-art image fusion methods. The experimental results show that the fusion image not only retains more the target information of infrared images, but also retains more detail information of visible images, which is superior to state-of-the-art methods in subjective evaluation and objective assessment.
Acta Photonica Sinica
- Publication Date: Sep. 25, 2021
- Vol. 50, Issue 9, 0910004 (2021)
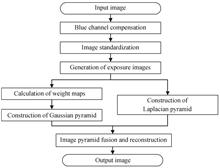
Sand-dust Image Enhancement Based on Multi-exposure Image Fusion
Hao CHEN, Huicheng LAI, Guxue GAO, Hao WU, and Xuze QIAN
To solve the problems of sand-dust image such as fuzzy detail, low contrast and color cast, an enhancement algorithm based on multi-exposure image fusion is proposed. Firstly, the blue channel is compensated to make up for the blue light loss of sand-dust image. Secondly, the RGB three channels of the image are standardized to reduce the deviation between the channel histograms, so as to remove the color cast. In order to obtain the details of different regions in the image, the linear transformation method of parameter control is used to generate multi-exposure images. Weight maps are calculated using quality measures of contrast, saturation and well-exposedness to select the best pixels in the exposure images. Then the Gaussian pyramid of weight maps and the Laplacian pyramid of exposure images are constructed. Finally, the image pyramid is fused and the resulting image is reconstructed. Subjective and objective experiments show that, compared with other algorithms, the proposed algorithm can effectively remove color cast and improve the contrast and clarity of the image, and the result image visual effect is good. To solve the problems of sand-dust image such as fuzzy detail, low contrast and color cast, an enhancement algorithm based on multi-exposure image fusion is proposed. Firstly, the blue channel is compensated to make up for the blue light loss of sand-dust image. Secondly, the RGB three channels of the image are standardized to reduce the deviation between the channel histograms, so as to remove the color cast. In order to obtain the details of different regions in the image, the linear transformation method of parameter control is used to generate multi-exposure images. Weight maps are calculated using quality measures of contrast, saturation and well-exposedness to select the best pixels in the exposure images. Then the Gaussian pyramid of weight maps and the Laplacian pyramid of exposure images are constructed. Finally, the image pyramid is fused and the resulting image is reconstructed. Subjective and objective experiments show that, compared with other algorithms, the proposed algorithm can effectively remove color cast and improve the contrast and clarity of the image, and the result image visual effect is good.
Acta Photonica Sinica
- Publication Date: Sep. 25, 2021
- Vol. 50, Issue 9, 0910003 (2021)
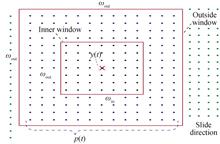
Hyperspectral Abnormal Target Detection Based on Extended Multi-attribute Profile and Fast Local RX Algorithm
Ruhan A, Xiaobin YUAN, Xiaodong MU, and Jingyi WANG
In order to further improve the speed and accuracy of hyperspectral abnormal target detection, a fast anomaly target detection method based on extended multi-attribute profiles and improved Reed-Xiaoli is proposed. Extended multi-attribute Profiles are extracted from the original hyperspectral images by mathematical morphological transformations. Moreover, a novel fast local Reed-Xiao algorithm is also proposed. Iteratively update inverse matrix of covariance using matrix inverse lemma, thereby reducing the computational complexity of the Mahalanobis distance. The combination of extended multi-attribute profiles and fast local Reed-Xiaoli detector effectively utilizes the spectral information and spatial information of hyperspectral images, it greatly improves the detection accuracy and reduce the running time. Experimental results on three real data sets show the AUC value of the algorithm in this paper is 0.996 7, 0.985 6 and 0.981 6 respectively. The operation time is 21.218 1 s, 15.192 8 s and 32.337 9 s respectively. The proposed method has obvious advantages in detection accuracy and speed, and has good practical value. In order to further improve the speed and accuracy of hyperspectral abnormal target detection, a fast anomaly target detection method based on extended multi-attribute profiles and improved Reed-Xiaoli is proposed. Extended multi-attribute Profiles are extracted from the original hyperspectral images by mathematical morphological transformations. Moreover, a novel fast local Reed-Xiao algorithm is also proposed. Iteratively update inverse matrix of covariance using matrix inverse lemma, thereby reducing the computational complexity of the Mahalanobis distance. The combination of extended multi-attribute profiles and fast local Reed-Xiaoli detector effectively utilizes the spectral information and spatial information of hyperspectral images, it greatly improves the detection accuracy and reduce the running time. Experimental results on three real data sets show the AUC value of the algorithm in this paper is 0.996 7, 0.985 6 and 0.981 6 respectively. The operation time is 21.218 1 s, 15.192 8 s and 32.337 9 s respectively. The proposed method has obvious advantages in detection accuracy and speed, and has good practical value.
Acta Photonica Sinica
- Publication Date: Sep. 25, 2021
- Vol. 50, Issue 9, 0910002 (2021)
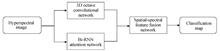
Hyperspectral Images Classification Method Based on 3D Octave Convolution and Bi-RNN Attention Network
Lianhui LIANG, Jun LI, and Shaoquan ZHANG
The traditional convolutional neural network model has substantial spatial feature information redundancy exists in the spatial dimension of the feature maps in hyperspectral image classification, and the spectral band data on a single pixel of the hyperspectral image are regarded as a disordered high dimensional vector for data processing, which does not conform to the characteristics of spectral data, which greatly affects the operational efficiency of the model and the performance of classification. In order to address this problem, a hyperspectral images classification method combined three-dimensional Octave convolution with bi-directional recurrent neural network attention network is proposed. Firstly, the 3D Octave convolution is exploited to capture spatial features of the hyperspectral image,and reduce spatial feature redundant information. Secondly, Bi-RNN spectral attention network is applied to regard spectral bands data as an ordred sequence to obtain spectral information of the hyperspectral image. Then, the spatial and spectral feature maps are connected by means of the fully connected layer to achieve features merge. Finally, the results of classification are outputed through softmax. Experimental results demonstrate that the classification accuracy of the method proposed reaches 99.97% and 99.79% in Pavia University and Botswana datasets. Compared with other mainstream methods, the proposed method can fully exploit spectral and spatial feature information, and own more competitive classification performance. The traditional convolutional neural network model has substantial spatial feature information redundancy exists in the spatial dimension of the feature maps in hyperspectral image classification, and the spectral band data on a single pixel of the hyperspectral image are regarded as a disordered high dimensional vector for data processing, which does not conform to the characteristics of spectral data, which greatly affects the operational efficiency of the model and the performance of classification. In order to address this problem, a hyperspectral images classification method combined three-dimensional Octave convolution with bi-directional recurrent neural network attention network is proposed. Firstly, the 3D Octave convolution is exploited to capture spatial features of the hyperspectral image,and reduce spatial feature redundant information. Secondly, Bi-RNN spectral attention network is applied to regard spectral bands data as an ordred sequence to obtain spectral information of the hyperspectral image. Then, the spatial and spectral feature maps are connected by means of the fully connected layer to achieve features merge. Finally, the results of classification are outputed through softmax. Experimental results demonstrate that the classification accuracy of the method proposed reaches 99.97% and 99.79% in Pavia University and Botswana datasets. Compared with other mainstream methods, the proposed method can fully exploit spectral and spatial feature information, and own more competitive classification performance.
Acta Photonica Sinica
- Publication Date: Sep. 25, 2021
- Vol. 50, Issue 9, 0910001 (2021)

Fast Blind Restoration of QR Code Images Based on Blurred Imaging Mechanism
Rongjun CHEN, Zhijun ZHENG, Huimin ZHAO, Jinchang REN, and Hongzhou TAN
A fast blind restoration method of QR code images was proposed based on a blurred imaging mechanism. On the basis of the research on the centroid invariance of the blurred imaging diffuse light spots, the circular finder pattern is designed. When the image is blurred, the centroid of the pattern and the position of the QR code symbol can be quickly detected by methods such as connected components. Moreover, combined with step edge characteristics, gradient and intensity characteristics, edge detection technology, and optical imaging mechanism, the defocus radius of the blurred QR code image can be quickly and accurately estimated. Furthermore, the Wiener filter is applied to restore the QR code image quickly and effectively. Compared with the other algorithms, the proposed method has improved deblurring results in both structural similarity and peak signal-to-noise ratio, especially in the recovery speed. The average recovery time is 0.329 2 s. Experimental results show that this method can estimate the defocus radius with high accuracy and can quickly realize the blind restoration of QR code images. It has the advantages of rapidity and robustness, which are convenient for embedded hardware implementation and suitable for barcode identification-related industrial Internet of Things application scenarios. A fast blind restoration method of QR code images was proposed based on a blurred imaging mechanism. On the basis of the research on the centroid invariance of the blurred imaging diffuse light spots, the circular finder pattern is designed. When the image is blurred, the centroid of the pattern and the position of the QR code symbol can be quickly detected by methods such as connected components. Moreover, combined with step edge characteristics, gradient and intensity characteristics, edge detection technology, and optical imaging mechanism, the defocus radius of the blurred QR code image can be quickly and accurately estimated. Furthermore, the Wiener filter is applied to restore the QR code image quickly and effectively. Compared with the other algorithms, the proposed method has improved deblurring results in both structural similarity and peak signal-to-noise ratio, especially in the recovery speed. The average recovery time is 0.329 2 s. Experimental results show that this method can estimate the defocus radius with high accuracy and can quickly realize the blind restoration of QR code images. It has the advantages of rapidity and robustness, which are convenient for embedded hardware implementation and suitable for barcode identification-related industrial Internet of Things application scenarios.
Acta Photonica Sinica
- Publication Date: Jul. 25, 2021
- Vol. 50, Issue 7, 91 (2021)
Remote Sensing Image Scene Classification Based on Supervised Contrastive Learning
Dongen GUO, Ying XIA, Xiaobo LUO, and Jiangfan FENG
To solve the problem of scene classification performance caused by complex background, intra-class diversity and inter-class similarity in remote sensing scene images, a new remote sensing scene classification method based on supervised contrast learning is proposed. The method involves two stages: discriminative feature learning and linear classification. In the stage of discriminative feature learning, a supervised contrastive loss first is introduced to narrow the distance between similar scenes and increase the distance between different types of scenes, so as to improve the scene discriminative ability of intra-class diversity and inter-class similarity; secondly, a gated self-attention module is introduced to filter useless background information and focus on key scene parts for improving scene recognition capabilities with complex backgrounds; finally, the pre-trained Inception V3 branch is introduced, and the branch features are merged with the final features extracted by the original model to further enhance the feature discriminative ability for improving the overall performance of scene classification. In the linear classification stage, the classification results are obtained by fine-tuning the model trained in the first stage. Comprehensive experiments on AID and NWPU-RESISC45 datasets demonstrate the effectiveness of the proposed method. To solve the problem of scene classification performance caused by complex background, intra-class diversity and inter-class similarity in remote sensing scene images, a new remote sensing scene classification method based on supervised contrast learning is proposed. The method involves two stages: discriminative feature learning and linear classification. In the stage of discriminative feature learning, a supervised contrastive loss first is introduced to narrow the distance between similar scenes and increase the distance between different types of scenes, so as to improve the scene discriminative ability of intra-class diversity and inter-class similarity; secondly, a gated self-attention module is introduced to filter useless background information and focus on key scene parts for improving scene recognition capabilities with complex backgrounds; finally, the pre-trained Inception V3 branch is introduced, and the branch features are merged with the final features extracted by the original model to further enhance the feature discriminative ability for improving the overall performance of scene classification. In the linear classification stage, the classification results are obtained by fine-tuning the model trained in the first stage. Comprehensive experiments on AID and NWPU-RESISC45 datasets demonstrate the effectiveness of the proposed method.
Acta Photonica Sinica
- Publication Date: Jul. 25, 2021
- Vol. 50, Issue 7, 79 (2021)
Bit-plane Motion Estimation for Digitally Driven Near-eye Display
Yuan JI, Yuansheng SONG, Yuansheng CHEN, Wendong CHEN, and Tingzhou MU
Near-eye display should be miniaturized under the premise of high resolution and high refresh rate, traditional video compression schemes can not meet the demand. The relationship between critical frequency of human eye and eccentricity is quantified, and a viewpoint just noticeable difference model for matching criteria of bit-plane motion estimation is proposed. Search range of the motion estimation is optimized into two parts: time dimension and gray scale dimension. Combined with the human visual system and probability statistical analysis, supplementary matching blocks are added to replace the residual data. A video compression scheme based on bit-plane motion estimation is developed for digitally driven near-eye displays, a controller is designed with field programmable gate array as the core and a system is built for verification. The experimental results show that the compression effect on the lower five bit-planes is the most balanced, the compression ratio is 1.385, and the data transmission volume is constant, which is beneficial to hardware design. The peak signal to noise ratio is 37.658 dB, and the structural similarity is 0.975. There is no obvious difference between the restored image and the original image, which is in line with the intuitive perception of the human eye. Near-eye display should be miniaturized under the premise of high resolution and high refresh rate, traditional video compression schemes can not meet the demand. The relationship between critical frequency of human eye and eccentricity is quantified, and a viewpoint just noticeable difference model for matching criteria of bit-plane motion estimation is proposed. Search range of the motion estimation is optimized into two parts: time dimension and gray scale dimension. Combined with the human visual system and probability statistical analysis, supplementary matching blocks are added to replace the residual data. A video compression scheme based on bit-plane motion estimation is developed for digitally driven near-eye displays, a controller is designed with field programmable gate array as the core and a system is built for verification. The experimental results show that the compression effect on the lower five bit-planes is the most balanced, the compression ratio is 1.385, and the data transmission volume is constant, which is beneficial to hardware design. The peak signal to noise ratio is 37.658 dB, and the structural similarity is 0.975. There is no obvious difference between the restored image and the original image, which is in line with the intuitive perception of the human eye.
Acta Photonica Sinica
- Publication Date: Jul. 25, 2021
- Vol. 50, Issue 7, 68 (2021)
Hyperspectral Unmixing Based on Constrained Nonnegative Matrix Factorization
Xiangxiang JIA, Baofeng GUO, Fanchang DING, and Wenjie XU
To obtain an improved optimal solution, a nonnegative matrix factorization method based on abundance and endmember constraints for hyperspectral unmixing is proposed. First, considering the sparseness of the abundance matrix, a weighted sparse regularization is introduced to the Nonnegative Matrix Factorization(NMF) model to ensure the sparseness of the abundance matrix. The weights are updated adaptively according to the abundance matrix. Second, given the priori knowledge of the distribution of adjacent pixels, a total variation regularization is further added to the NMF model to promote the smoothness of the abundance map. Finally, a new constraint given by a potential function from the Markov random field model is introduced to improve the spectral smoothness of the endmembers. Experiments are conducted to evaluate the effectiveness of the proposed method based on three different data sets, including a synthetic data set and two real-life data sets (Jasper Ridge and Cuprite) respectively. From the experimental results, it is found that the proposed method got better performances both on the spectral similarity and the estimation accuracy for abundance. To obtain an improved optimal solution, a nonnegative matrix factorization method based on abundance and endmember constraints for hyperspectral unmixing is proposed. First, considering the sparseness of the abundance matrix, a weighted sparse regularization is introduced to the Nonnegative Matrix Factorization(NMF) model to ensure the sparseness of the abundance matrix. The weights are updated adaptively according to the abundance matrix. Second, given the priori knowledge of the distribution of adjacent pixels, a total variation regularization is further added to the NMF model to promote the smoothness of the abundance map. Finally, a new constraint given by a potential function from the Markov random field model is introduced to improve the spectral smoothness of the endmembers. Experiments are conducted to evaluate the effectiveness of the proposed method based on three different data sets, including a synthetic data set and two real-life data sets (Jasper Ridge and Cuprite) respectively. From the experimental results, it is found that the proposed method got better performances both on the spectral similarity and the estimation accuracy for abundance.
Acta Photonica Sinica
- Publication Date: Jul. 25, 2021
- Vol. 50, Issue 7, 113 (2021)
Research on Denoising Method for Polarization Degree Image and Polarization Angle Image of Dim and Weak Targets
Shuzhuo MIAO, Cunbo FAN, Guanyu WEN, Jian GAO, and Guohai ZHAO
Aiming at the problems of strong background noise and indistinct detail contour features in polarization fusion image of dim and weak targets, considering to the difference of gray level between Gaussian background noise and target contour in degree of polarization image, a denoising algorithm based on noise template threshold matching is proposed. Analyzing the gray correlation between the sub-image of pure noise and the sub-image of target contour in the angle of polarization image, a denoising algorithm based on Region Gray Correlation Matching (RGCM) is proposed, compared with the traditional denoising methods, the RGCM algorithm can effectively remove a large amount of background noise and retain the target contour features better. The experimental results of polarization image fusion further prove that the algorithm proposed in this paper can not only improve the contrast of dim and weak targets but also significantly improve the image quality in polarization fusion enhancement image. Aiming at the problems of strong background noise and indistinct detail contour features in polarization fusion image of dim and weak targets, considering to the difference of gray level between Gaussian background noise and target contour in degree of polarization image, a denoising algorithm based on noise template threshold matching is proposed. Analyzing the gray correlation between the sub-image of pure noise and the sub-image of target contour in the angle of polarization image, a denoising algorithm based on Region Gray Correlation Matching (RGCM) is proposed, compared with the traditional denoising methods, the RGCM algorithm can effectively remove a large amount of background noise and retain the target contour features better. The experimental results of polarization image fusion further prove that the algorithm proposed in this paper can not only improve the contrast of dim and weak targets but also significantly improve the image quality in polarization fusion enhancement image.
Acta Photonica Sinica
- Publication Date: Jul. 25, 2021
- Vol. 50, Issue 7, 100 (2021)
Topics
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20